 Release Info
Release Info Downloads
Downloads Documentation
Documentation Support
Support Partners
Partners User Forum
User Forum


 |
Go Global with DBCS and Unicode |
One of the major problems developers face when taking their applications overseas, in particular to the Asian markets, is the need to display and process different character sets. We would not be much of a worldwide distributor if we did not address this need.
Effective in build 9159, PxPlus now supports both DBCS and UNICODE characters sets opening a whole new world for your applications.
Character Sets:
Two methods are commonly used to handle extended character sets. One method is DBCS/MBCS (Double Byte Character Set/Multi-Byte Character Set) and the other is Unicode.
DBCS/MCBS allows data to consist of either a single byte or multiple bytes (generally two). Most common ANSI characters (0-9, A-Z, etc) are represented by a single character. Multiple characters (a lead-in or escape followed by another) represent characters that are more exotic, such as those found in the Chinese or Japanese character set.
Unicode represents all characters as two bytes allowing for up to 64K different characters.
The PxPlus Approach:
The approach taken by PxPlus has been designed to minimize the impact on your applications allowing you to preserve the vast majority of your existing code.
While many newer applications use Unicode in order to support extended characters, the transition from a one-byte character world to a two-byte character world is not simple. Many applications make system calls or access files where they need to access a specific number of bytes based on the type of hardware they are using. Some applications have Hex values in the code such as $FF$ which are intended to represent the ‘Highest’ character value or other hard coded hex values.
To minimize the impact on your application when it is enabled to use the extended character sets, we decided to use DBCS internally for most data representation. This will satisfy the needs of most applications with a minimum of retrofit requirements. An additional benefit of this approach is that existing values used for most of the more common characters do not change – for example a quote is still $22$ not $0022$
In addition to DBCS, PxPlus also provides direct access to Unicode translations for those applications that need Unicode (see Unicode Translation).
Using DBCS:
In order to use DBCS, PxPlus needs to determine which character set or ‘codepage’ to use in order to represent the data. Generally, all character sets will use the same values for characters whose values are between $00$ and $7F$ (basic ANSI alphanumerics and symbols). Characters $80$ and above change based on the character set you chose.
To simplify the process of defining the character set to use, PxPlus uses the character set defined for the base text font on the system. This is the font selected using ALT-Space, Font from the windows screen.
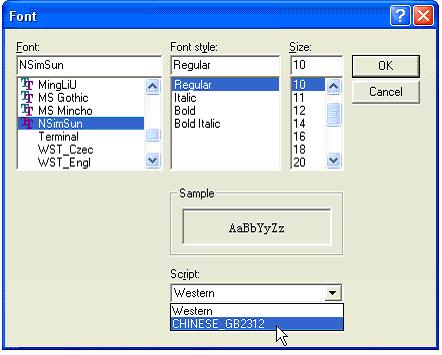
Select the desired font you wish to use and the then the desired character set (Script) to use with that Font. Note that not all Fonts work with all Character sets.
Once selected, all characters used by the system will utilize this character set. The setting is maintained by the system in the Charset entry, Font section of the INI file.
The approach used by PxPlus allows for the use of different characters on different systems, usually based on where the application is running. All workstations using the application need to use the same character set in order to assure the consistency of the data.
Internal Character Values:
Two values are used by the system to control access to the current character mappings.
The first value is the character set number. This is the value that Windows assigns to a font in order to define which character set the font uses. Some of the common character sets are:
| 0 | ANSI_CHARSET |
| 2 | SYMBOL_CHARSET |
| 128 | SHIFTJIS_CHARSET |
| 129 | HANGEUL_CHARSET |
| 134 | GB2312_CHARSET |
| 136 | CHINESEBIG5_CHARSET |
| 255 | OEM_CHARSET (Old PC Dos characters) |
These numbers can be used on any FONT specification within ProvideX by preceding the numeric value by a % in the Font attributes.
The second value is the number assigned to the codepage translation table. This is a numeric value assigned to the table to use when translating data between DBCS and UNICODE. The default codepage number is 1252 for normal ANSI data.
These two values can be retrieved from the following TCB values:
TCB(504) -- Current character set
TCB(505) -- Current codepage number
The TRANSLATE directive has been extended to convert the extended data between DBCS and UNICODE. The new format for the Translate directive is:
TRANSLATE FROM <inputstr> [, TBL=nn ] TO <strvar$> [, TBL=nn ]
This directive can be used to translate data from DBCS to UNICODE, UNICODE to DBCS, or two different DBCS forms (different codepages). It will take the string provided in <inputstr> and convert it into <strvar$>. Various options exist:
- If no TBL= options are specified, the system will translate DBCS from <inputstr> to UNICODE into <strvar$>. It will use the current default codepage to accomplish this translation.
- If a TBL= option exists only on the <inputstr>, the data will converted from DBCS to UNICODE based on the codepage table specified.
- If a TBL= option only on the <strvar$> the system will convert UNICODE to DBCS using the codepage table specified.
- If the TBL= option exists on both, the data will be translated from DBCS to DBCS changing the codepage table.
If desired you can specify TBL=* to indicate that you want to use the current default codepage.
Examples:
TRANSLATE FROM USER_INPUT$ TO DB_DATA$
- Convert USER_INPUT$ from DBCS to UNICODE into DB_DATA$
TRANSLATE FROM DB_DATA$ TO USER_OUTPUT$,TBL=*
- Convert DB_DATA$ from UNICODE to DBCS into USER_OUTPUT$
conversion based on current character set chosen by the user.
Workstart Setup:
Click here to view a short tutorial on how to setup your workstation for use with the extended character sets in PxPlus.
Current Limitations:
Presently, the extended character support is limited to the Windows version of PxPlus or when using WindX in any supported server configuration. JavX does not support the use of the Extended Character set.
The TRANSLATE directive and TCB values are ONLY available on a Windows system.
Future Considerations:
Additional features are planned to allow for direct access of UNICODE data from Windows Controls and databases.
